L'apprendimento automatico è in grado di identificare le specie vettore e predire le epidemie?

Gli ecologi sono impegnati da tempo nella ricerca dei “serbatoi” animali che ospitano e trasmettono il virus all’uomo (spesso senza ammalarsi a loro volta) poiché si crede che il contagio avvenga tramite il contatto con esemplari infetti. A ogni nuovo focolaio di zoonosi, come nel caso dell’infezione da Ebola, gli scienziati lavorano alacremente per individuare le riserve animali affinché le autorità sanitarie possano identificare le modalità di contagio e, magari, fermare il salto di specie, cioè il passaggio dall’animale infetto all’uomo. Attualmente, la gestione delle epidemie è di tipo reattivo, cioè avviene dopo la loro manifestazione.
A Meliadou, i ricercatori intervistarono gli abitanti, studiarono le popolazioni di primati delle foreste circostanti e catturarono pipistrelli. Nel dicembre 2014 pubblicarono una relazione nella quale ipotizzavano che il piccolo Emile avesse contratto il virus da una colonia di pipistrelli insettivori annidata nella cavità di un tronco, dove il bambino andava spesso a giocare. L’albero, però, bruciò prima che gli studiosi arrivassero nel villaggio, per cui non vi è totale certezza.
![Il (probabile) focolaio: secondo gli epidemiologi l’attuale epidemia causata dall’Ebola ha avuto origine nel villaggio guineano di Meliandou [in alto a destra]. Un bambino sarebbe stato infettato dal virus mentre giocava nei pressi di albero con una cavità [a sinistra], rifugio di una colonia di pipistrelli dalla coda libera dell'Angola [in basso a destra].](https://cdn.peacelink.it/images/20862.jpg?format=jpg&w=300)
Mi occupo di ecologia delle infezioni al Cary Insitute of Ecosystem Studies, a Millbrook, nello Stato di New York, e mi servo della modellazione informatica e dell’apprendimento automatico per prevedere quali specie possono essere responsabili di future epidemie. I modelli che genero creano il “profilo” dei probabili serbatoi identificando l’insieme di caratteristiche che contraddistinguono le specie non comuni che possono ospitare agenti pericolosi per l’uomo. In seguito utilizzo degli algoritmi per ordinare centinaia o migliaia di specie che non sono ancora state esaminate per la presenza di zoonosi e per calcolare la probabilità che sia un serbatoio sulla base della sua somiglianza con il profilo creato. Questi modelli forniscono una lista di sospettati.
È un lavoro che i miei colleghi e io svolgiamo con criteri scientifici e anche con forte determinazione. Le malattie infettive sono in aumento in tutto il mondo e, secondo l’agenzia degli Stati Uniti per lo sviluppo internazionale, le zoonosi rappresentano il 75 per cento delle nuove infezioni. Prevedere quali specie potrebbero ospitare agenti patogeni trasmissibili all’uomo permette di monitorare i potenziali luoghi a rischio in cui avviene il contatto con questi animali. Spero che, così come i meteorologi prevedono il meteo, un giorno i biologi possano prevedere lo scoppio delle epidemie, ma con una differenza principale: mentre i primi non possono fermare l’arrivo di un temporale, noi potremmo riuscire a prevenire le epidemie.
Come funziona l’apprendimento automatico
Questo diagramma estremamente semplificato mostra il procedimento con cui il nostro algoritmo genera gli alberi di classificazione che poi vengono utilizzati per predire quali specie di roditori sono vettori di zoonosi.
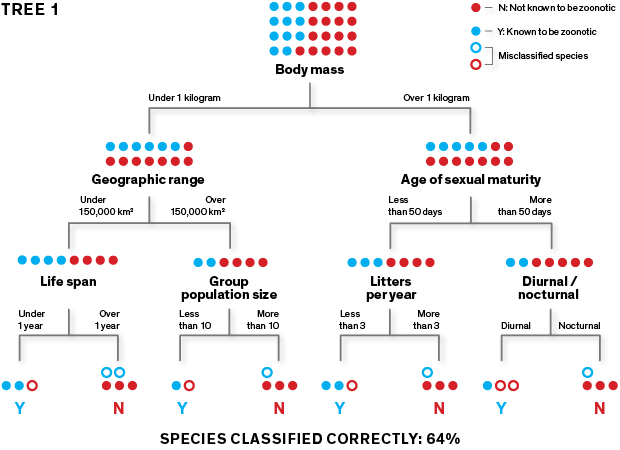
L’algoritmo apprende a classificare le specie in “zoonotiche” (rappresentate qui dalla “Y”) o “non conosciute come zoonotiche” (rappresentate dalla “N”) utilizzando un training set. L’albero iniziale viene creato partizionando ripetutamente i data set delle specie di roditori in due gruppi sulla base di un attributo selezionato a caso (ad esempio: taglia maggiore o minore di un kilogrammo) per ciascuna partizione. Lo scopo è di separare le Y dalle N nelle “foglie” finali dell’albero.
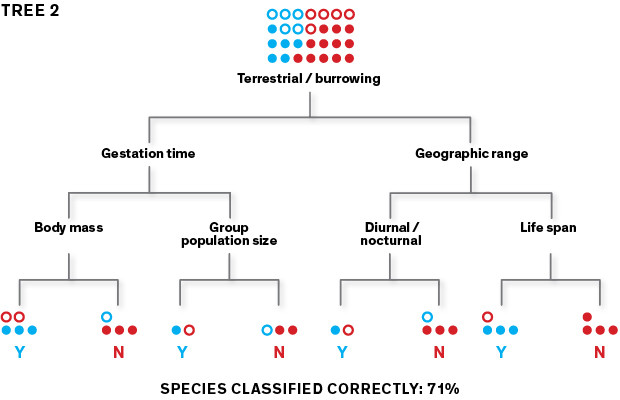
Poiché il primo albero può generare numerosi errori di classificazione, l’algoritmo ne crea un secondo che attribuisce la priorità alle specie classificate erroneamente al fine di ripartirle correttamente. Alle specie del secondo albero non classificate correttamente viene attribuita nuovamente la priorità generando così un terzo albero e così via.
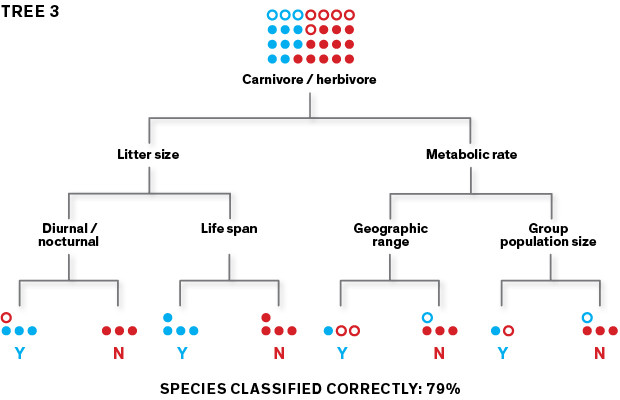
Questo procedimento iterativo genera migliaia di alberi. Quando i dati vengono filtrati attraverso tutti questi alberi fino a generare un insieme, l’accuratezza della classificazione aumenta. Una volta che il modello funziona con i training data, verrà utilizzato per la predizione con i data set rimanenti.
Per comprendere perché fino a oggi è prevalso un approccio di tipo reattivo nella gestione delle epidemie, pensiamo al virus Ebola. Immaginiamo di essere un biologo, esperto di fauna selvatica, alla ricerca dei serbatoi virali nella zona del focolaio originario, cioè nella foresta fluviale congolese. Ci troveremmo di fronte a un’area di dimensioni simili all’Alaska, abitata da oltre 1.400 specie di mammiferi e volatili, e da infinite specie di insetti. Se disponessimo delle risorse, potremmo provare a campionare tutti gli animali che riusciamo a catturare: molti esemplari delle specie comuni e, ogni tanto, qualcuno appartenente a quelle rare.
Probabilmente, nemmeno così raggiungeremmo il nostro scopo. Solamente una minima parte della popolazione delle specie ospite sarà infetto e, poiché questo tipo di epidemia si manifesta in modo discontinuo, la diffusione nei serbatoi animali sarà molto bassa. Inoltre, ci potrebbero essere diverse specie portatrici e la ricerca avviene in un ambiente dinamico in cui gli animali migrano in base alle stagioni e si spostano in seguito alla distruzione del loro habitat. Anche nel caso in cui riuscissimo a catturare un esemplare infetto, potrebbe essere difficile identificare il virus poiché la concentrazione nel corpo varia in relazione alla stagione o ai livelli di stress.
Le precedenti indagini per la ricerca dei serbatoi tra la fauna selvatica hanno portato alla cattura di oltre 30.000 esemplari fra centinaia di specie. Nel sangue di alcuni sono state trovate tracce di infezioni precedenti (ossia anticorpi), ma, fino a oggi, il virus vivente non è ancora stato isolato. Le ricerche continueranno, ma è chiaro che un nuovo approccio sarebbe auspicabile.
Gli algoritmi di apprendimento automatico che utilizzo per il mio lavoro elaborano numerose quantità di dati non strutturati sulla fauna selvatica e identificano i tratti chiave più utili per predire quali sono le specie serbatoio. Derivano da strumenti conosciuti da decenni chiamati alberi di classificazione e regressione e la novità è rappresentata dall’applicazione a una sfida enorme nell’ambito dell’ecologia e della salute globale.
Il mio recente studio sui roditori, condotto assieme ai colleghi dell’Università della Georgia, spiega il funzionamento di questo approccio. L’ordine dei Rodentia include oltre 2.200 specie, più di ogni altro gruppo di mammiferi. Questi animali sono fonte di numerosi agenti patogeni: sappiamo che oltre 200 specie, secondo le nostre stime conservative, possono trasmettere da una a undici zoonosi. Tra le infezioni trasmissibili all’uomo rientrano quelle da Hantavirus, responsabile di malattie polmonari letali, e la peste bubbonica che è causata da un batterio.
Per addestrare l’algoritmo a identificare nuovi vettori, abbiamo immesso l’80 per cento dei dati di tutte le specie di roditori conservando i rimanenti per i test. A ciascuna abbiamo attribuito un’etichetta binaria: “1” per indicare che è un vettore noto di zoonosi e “2” per indicare che la condizione di vettore non è nota. Inoltre, abbiamo immesso dati da fonti come PanTHERIA, un vasto database sui mammiferi che raccoglie informazioni da migliaia di studi in campo sulla fisiologia, il comportamento, la distribuzione geografica, la struttura sociale etc. di questi animali.
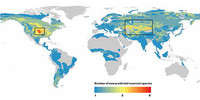
Il nostro modello ha identificato cinquantotto roditori che finora non erano mai stati associati a zoonosi e non erano considerati possibili serbatoi di agenti patogeni trasmissibili all’uomo. La mappa di questi ha messo in luce due potenziali aree a rischio di epidemie: il Midwest negli Stati Uniti e una fascia che attraversa l’Asia centrale e il Medio Oriente. Sulla base di queste previsioni, i biologi che operano in campo possono analizzare le zone e studiare le specie presenti sulla nostra lista di sospettati, come il topo delle cavallette e il merione.
Nel nostro studio, l’algoritmo ha generato un albero selezionando un attributo a caso per partizionare il gruppo delle specie di roditori in due sottogruppi omogenei: “1” e “0”. Per quanto accurato, è inevitabile che compia errori di classificazione, quindi ha selezionato un secondo attributo e poi un terzo e così via fino a partizionare tutti i roditori nelle foglie. I tratti includevano il tasso metabolico a riposo, la taglia dell’adulto, l’età della maturità sessuale, il numero di piccoli per figliata, il numero di figliate all’anno, la numerosità della popolazione di un gruppo e oltre cinquanta caratteristiche simili.
Questo metodo ha un grosso punto debole: viene facilmente condizionato dalla variabile che viene scelta per prima. Infatti, in relazione all’attributo selezionato dall’algoritmo, ad esempio “numerosità della popolazione di un gruppo” o “tasso metabolico”, verranno generati alberi diversi. Utilizzandone uno qualsiasi non siamo in grado di predire correttamente se un nuovo roditore è un potenziale portatore di zoonosi o meno, sarebbe quasi come fare testa o croce. Per superare il problema dell’accuratezza di predizione si usa un procedimento iterativo chiamato boosting. L’algoritmo si concentra sugli errori commessi per ogni albero assegnando la priorità a questi dati per generare dei nuovi alberi. Ne verranno creati, così, centinaia o migliaia con valore scarsamente predittivo che, però, se utilizzati come un insieme, produrranno un modello altamente affidabile.
Nella fase di test, condotto sul 20 per cento dei dati non inclusi nel training data set, l’algoritmo è stato in grado di predire le specie serbatoio con un’accuratezza del 90 per cento. Andando poi a verificare quali attributi fossero stati utilizzati, è emerso che le riserve virali erano state identificate sulla base di un trait profile distintivo. A differenza di quanto ci si sarebbe aspettati, l’algoritmo non aveva selezionato le specie strettamente correlate l’una all’altra, bensì aveva scoperto che quelle serbatoio si distinguevano per un ciclo vitale “rapido”, con un tasso di crescita veloce, una maturità sessuale precoce e frequenti figliate. Questa scoperta è coerente con approfonditi studi su singoli roditori secondo i quali le specie serbatoio avrebbero un sistema immunitario meno sensibile. Questi animali resistono agli agenti patogeni grazie a una strategia del tipo “vivi rapidamente e muori presto”: le difese immunitarie non sono fondamentali perché devono restare sani quanto basta per riprodursi. Dal profilo è emerso che questi animali hanno un’ampia distribuzione geografica perché sono in grado di proliferare in habitat ecologici diversi o adattarsi all’ambiente frammentario ed eterogeneo dell’uomo.
Questo studio non ha fornito solo un contributo scientifico, ma anche dati elaborabili. Analizzando oltre 2.200 specie di roditori, l’algoritmo ha creato una lista di nuovi sospettati. Alcune specie, che in precedenza erano state classificate come “0” in quanto non conosciute come serbatoi virali, ora rientrano nella categoria “1” che include i vettori di zoonosi. Non abbiamo dovuto attendere molto per la validazione. Infatti, mentre stavamo pubblicando i risultati, due delle specie sospettate sono state identificate come nuove portatrici di malattie trasmissibili all’uomo. Una di queste, l’arvicola rossastra (Myodes gapperi), originaria del Canada e degli Stati Uniti settentrionali, è serbatoio del parassita dell’echinococcosi, una malattia grave che causa la formazione di cisti in diversi organi. L’altra è un criceto (Microtus guentheri), originario dell’Asia Minore, che è risultato essere un nuovo vettore della leishmaniosi, responsabile di ulcere cutanee.
La nostra lista dei sospettati offre ai biologi l’opportunità di verificare sul campo i nostri risultati. Gli studi sul campo forniranno, a loro volta, informazioni per il nostro lavoro. La continua osservazione e la scoperta di nuovi vettori di zoonosi arricchiranno il nostro data base e i modelli di predizione diventeranno più precisi. L’algoritmo, infatti, si evolverà continuando ad apprendere.
Attualmente, stiamo applicando questi metodi per contribuire alla lotta contro altre malattie devastanti. Ad esempio, stiamo cercando di identificare quali altre specie di pipistrelli possono fungere da serbatoio di filovirus come l’Ebola e il Marborg che provocano febbri emorragiche. Speriamo che i nostri risultati contribuiscano a spiegare perché certi pipistrelli riescono a vivere con un infezioni così letali per le scimmie antropomorfe e l’uomo.
Il nostro modello ha già identificato un insieme di specie di pipistrelli presenti su una lista di controllo. Con nostra sorpresa, alcune di quelle ritenute potenziali vettori di Ebolavirus vivono al di fuori dell’Africa, in aree dalle quali non si hanno segnalazioni ufficiali di focolai umani di febbri emorragiche. Questi risultati sollevano una questione per i biologi: se è vero che in queste zone non si sono verificate epidemie, qual è il motivo? Ma anche le autorità sanitarie devono porsi una domanda: è il caso di preoccuparsi?
L’apprendimento automatico offre dei vantaggi fondamentali per l’ecologia, una disciplina che cerca di comprendere le interazioni complesse e dinamiche tra miliardi di esseri viventi che sgomitano per un posto sulla Terra.
Ad esempio, mentre il nostro algoritmo permette di gestire dei data set incompleti, i biologi non possono imparare tutto sul milione e seicentomila specie catalogate finora, per non parlare dei milioni che ancora non lo sono. La presenza o assenza di una particolare informazione, infatti, viene trattata come un’altra variabile che può fungere da punto di ramificazione negli alberi di classificazione.
Il nostro approccio, inoltre, elimina i bias di campionamento che possono distorcere l’analisi delle malattie infettive: ampie ricerche sulla fauna selvatica condotte in aree sviluppate come gli Stati Uniti e l’Europa hanno fornito dati di migliore qualità sulle specie americane ed europee. Inoltre, un biologo potrebbe incorrere in bias selettivi nello studio delle singole specie ospite: più si ricerca qualcosa, più è probabile trovarla. Ad esempio, scoprire che il ratto norvegese è portatore della malattia X, porta a una maggiore probabilità che venga campionato anche per Y e Z, con il risultato che qualche specie potrebbe sembrare addirittura un concentrato di agenti patogeni, a discapito di altre che non verrebbero campionate.
Concentrandosi sulle caratteristiche intrinseche delle specie, il nostro metodo riduce al minimo le conseguenze di questi errori. Per esempio, se l’algoritmo seleziona le specie di roditori di piccola taglia, includerà quelle di tutto il mondo (perché è probabile che i piccoli roditori vivano tanto nei paesi sviluppati quanto in quelli sottosviluppati). L’utilizzo dei tratti biologici intrinseci per predire quali siano i serbatoi consente di non cadere nella trappola del bias selettivo: innanzitutto, effettuando previsioni in aree che possono essere sorvegliate. Dall’altro lato, però, non si può fare molto se i dati mancanti sono numerosi. Se non si dispone di informazioni su una specie, non sarà possibile prevedere la probabilità che sia un serbatoio virale. Questo lavoro dimostra che i tagli ai finanziamenti alla scienza di base hanno ripercussioni significative. Per questo motivo vale veramente la pena conoscere la vita di un topo sconosciuto che vive in Papua Nuova Guinea.
L’apprendimento automatico consente, inoltre, di gestire la complessità. Le analisi ecologiche spesso includono decine di variabili, ma non è sempre chiaro come interagiscano. Ad esempio, sebbene ci siano sufficienti prove per dimostrare che la taglia di un animale è proporzionale al suo tasso metabolico in base a una particolare relazione matematica, non è completamente nota la relazione tra questi due fattori in un esemplare appena nato. Maggiori sono le variabili, più è difficile capirne la complessità e le interazioni che si celano dietro.
Alcune specie, ritenute possibili riserve di Ebolavirus, vivono al di fuori dell’Africa, in aree dove non si sono registrate epidemie.
L’algoritmo, però, non ha bisogno che fissiamo le regole di queste interazioni poiché a parlare sono gli stessi dati. Se una particolare combinazione di variabili porta a un’elevata stima di previsione, queste vengono identificate e presentate al ricercatore per la successiva interpretazione. L’algoritmo ignora le loro modalità di interazione poiché il suo scopo è massimizzare la capacità di predizione. È a questo punto che intervengono gli scienziati ai quali spetta osservare le variabili più importanti per la predizione e comprendere quello che rivelano sulla biologia delle riserve di agenti zoonotici.
Capire quale malattia insorge dal contatto con un dato serbatoio non è sufficiente per raggiungere l’obiettivo ambizioso di prevedere e addirittura prevenire le epidemie di natura zoonotica. I biologi devono capire perché una data specie è speciale e il nostro approccio ci fornisce un indizio proprio su questo, cioè sui meccanismi biologici che rendono un animale ospite e vettore di infezioni mortali.
Certamente anche l’uomo ha un ruolo nell’insorgenza delle malattie poiché spesso entra in contatto diretto con la fauna selvatica come anche i suoi animali domestici. Ne è un esempio il virus Nipah, originario della Malesia, e trasmesso all’uomo da dei maiali infetti che, a loro volta, erano stati contagiati dai pipistrelli della frutta. Questi avevano iniziato a nutrirsi nei frutteti e nelle fattorie di suini in seguito al taglio delle foreste nelle quali vivevano.
A causa dell’urbanizzazione, della deforestazione e della caccia, l’uomo continuerà a entrare in contatto con le specie selvatiche che sono potenziali portatrici di nuove zoonosi. Apparteniamo tutti allo stesso biosistema e le malattie nascono dalla sua complessità. La comprensione delle dinamiche ecologiche è solo all’inizio. Predire quali sono le specie serbatoio è una sfida, ma, per come la vedo io, fa parte di una sfida ancora più grande: capire come vivere in armonia con gli animali selvatica con i quali condividiamo il pianeta.